人生纲领
大学之道,在明明德,在新民,在止于至善
博学,审问,慎思,明辨,笃行
人生纲领
大学之道,在明明德,在新民,在止于至善
博学,审问,慎思,明辨,笃行

文章详细介绍了RAG的整个流程及关键节点
导读:
GPT胡说八道现象,根源在于——模型幻觉问题(AI Hallucination现象),这是由多种原因导致。
在生成文本时,大型语言模型依赖于统计概率来预测下一个最可能的词汇,而不是基于事实进行查询,这可能导致信息错误。
AI的回答局限在训练数据范围内,大模型并不掌握个人信息,或者公司内部的私有信息,对于超出训练数据范围的问题,就容易“胡说八道”。
现阶段,基于Transformer架构的模型,还无法彻底杜绝AI幻觉。但是,给大模型外挂知识库,补足其知识短板,就能有效减少模型幻觉问题,这一方法便是RAG——检索增强生成(Retrieval-Augmented Generation)。
检索增强生成(RAG)是一种AI框架,它通过将大语言模型与外部信息相整合,来提升模型的输出质量。
RAG从外部知识库中,检索相关的上下文(content),并将这些信息连同用户的问题,一起传递给大语言模型,从而提高输出的准确性和可靠性。
想象一下,您是一家汽车公司的高管,你希望为公司创建一个客户支持聊天机器人,以回答用户关于产品规格、故障排除、保修信息等方面的问题,用户提出了一个有关汽车中控显示屏出现故障的问题,客服机器人借助于RAG技术准确回答了用户的问题。如何做到的呢?
第一,RAG能减少幻觉问题。
第二,RAG能够为大语言模型注入最新资讯,及特定领域的关键信息,帮助模型生成更精准、更贴合需求的回答。
第三,在实际应用中,模型微调(fine-tuning)不仅成本高昂,而且每当模型更新时,都需要重新进行这一复杂过程,相比之下,RAG提供了一种高效而低成本的方案,因此成为推动AI技术落地实施的关键手段之一。
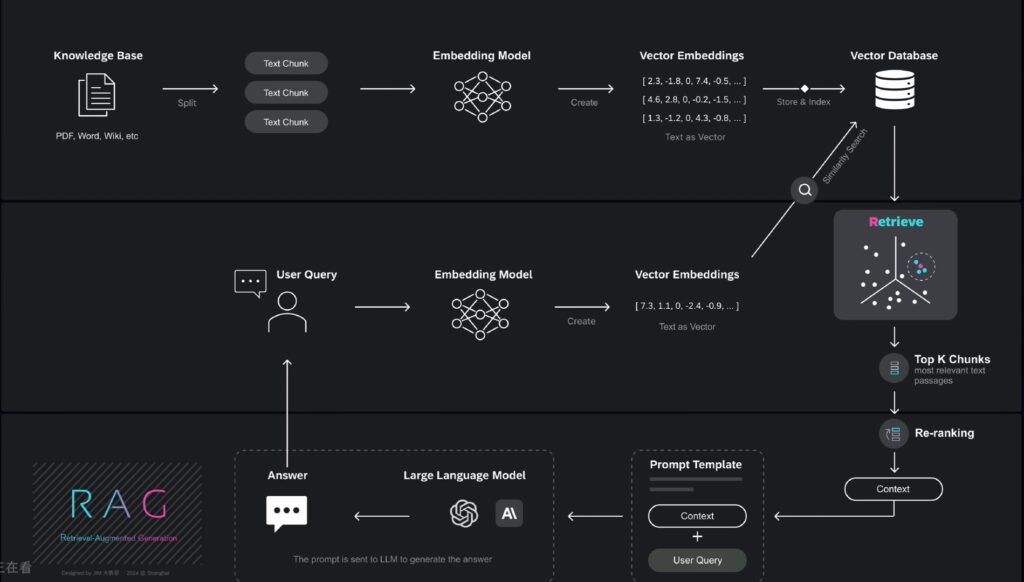
RAG工作流程的首要步骤,是针对知识库内各类格式的文档,如PDF、Word、Wiki等,进行处理。
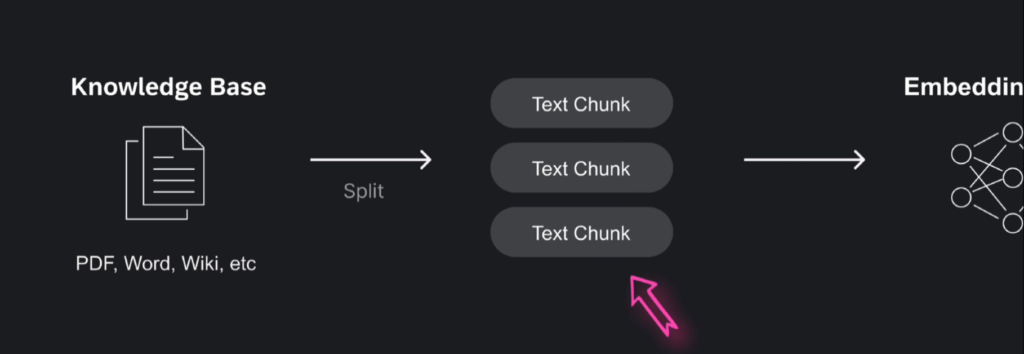
在RAG流程中,对知识文档进行分割,是一个至关重要的步骤,文档分割的质量,直接决定了检索的准确性和生成模型的效果。
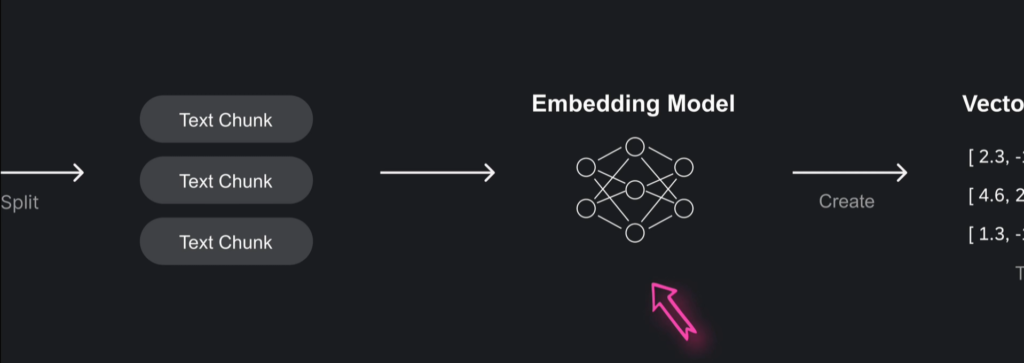
将文本分割成有意义的片段或“块”的过程,叫做文本分块,它能显著改善信息检索和内容生成效果,提供更精准相关的结果。
这些文本块,将由嵌入模型(Embdding Model)转换为向量。
Embedding Model是一种机器学习模型,它可以将高维输入数据,如文本、图像转换为低维向量,在RAG中,嵌入模型将文本块转换为向量,这些向量捕捉了文本的语义信息,从而可以从海量文本库中检索相关内容。
有多种模型可以用来生成向量嵌入,比如可以使用OpenAI的text-embedding-3-large模型。请注意不同模型生成的向量数值可能会有所不同。这就是嵌入模型生成的Vector Embedding向量嵌入。
向量嵌入(Vector Embedding)是嵌入模型生成的结果,是用一组数值表示的数据对象。向量嵌入捕捉了文本、图像或音频的语义和关联,在多维空间中呈现了出来,可以让机器学习算法能够更轻松地对其进行处理和解读。
原始数据经由嵌入模型,被转化成了向量嵌入(一组数值),从高维数据转换成了低维向量空间。在这个过程中,每个原始数据点都被映射成一个新的向量,这个向量捕捉了原始数据的一些关键特性或属性。

比如“I Love Tennis.”这句话,我们先把“I Love Tennis.”转换为几个token,再用Embedding Model(嵌入模型)来生成Embeddings,比如单词 I 就转换为向量嵌入。所谓向量,就是一个数字数组,其中每个数值表示对象在特定维度上的特征或属性。
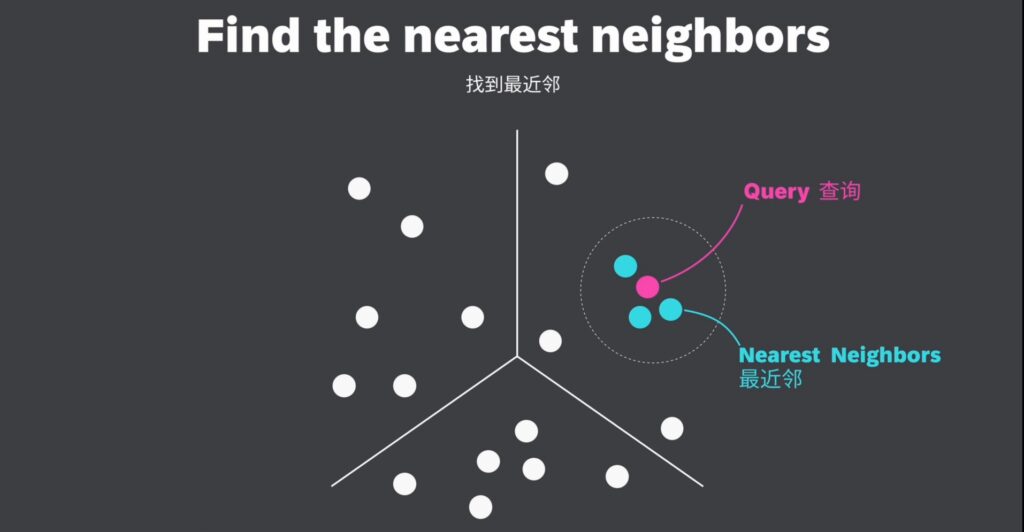
向量嵌入能够以数值形式,捕捉对象间的语义关系,可以通过向量搜索(也称为相似性搜索),在向量空间中来查找相似对象。如图,与查询向量(Query)距离最近的邻居,便是最相似的对象。
举例:有3个词,:cat(猫),kitty(小猫),apple(苹果),用神经网络模型把它们转化为向量嵌入。如果我们仔细观察它们的向量数值,会发现猫和小猫的向量数值非常相似,数值上相近的向量嵌入在语义上也是相似的。这里猫cat和小猫kitty,在语义上高度相关,尽管他们的拼写完全不同。
观察 kitty(小猫)和apple(苹果)的向量嵌入,我们会发现它们的数值差异显著,这表明它们在语义上并不相似。
这是OpenAI的一个三维可视化实例,在向量空间中,包含了动物、运动员、电影、交通工具、村庄等多个类别的向量,这些不同的类别在向量嵌入空间中,形成了5个清晰的簇。
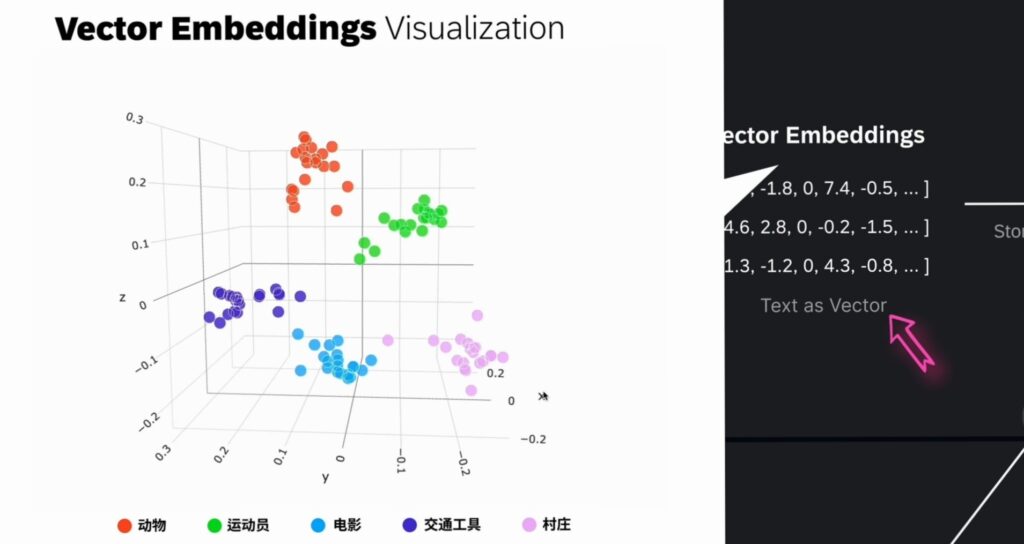
在这个例子中,与动物相关的数据点聚集在一起,与运动员相关的数据点也形成了一个独立的聚集区域。
请注意,通常的Embedding具有数百甚至数千个维度,为了实现向量空间的可视化,这里采用了PCA技术,将嵌入维度从2048维降低到了三维,相似的对象在向量空间中会靠得更近,而不相似的对象则会分散的更远。
那么这些 Embeddings 存储在哪里呢?它们存储在向量数据库中。
向量数据库是一种专门用于存储和检索高维向量数据的数据库,他们主要用于处理与相似性搜索相关的任务。向量数据库能够存储海量的高维向量,这些向量可以表示数据对象的特征。向量数据库可以作为AI系统的长期记忆库。当前一些专业厂商提供高性能的向量数据库解决方案,例如Pinecone等。

向量存储在向量数据库中,这些向量主要是由非结构化数据,通过嵌入模型(Embdding Model)转化而来的。所谓的非结构化数据(Un-structured Data),如文本、视频和音频,占全球数据的大约80%,它们通常来源于人类生成的内容,不易以预定义格式存储,这类数据可以通过转换为向量,有效地存储在向量数据库中,以便进行管理和检索。
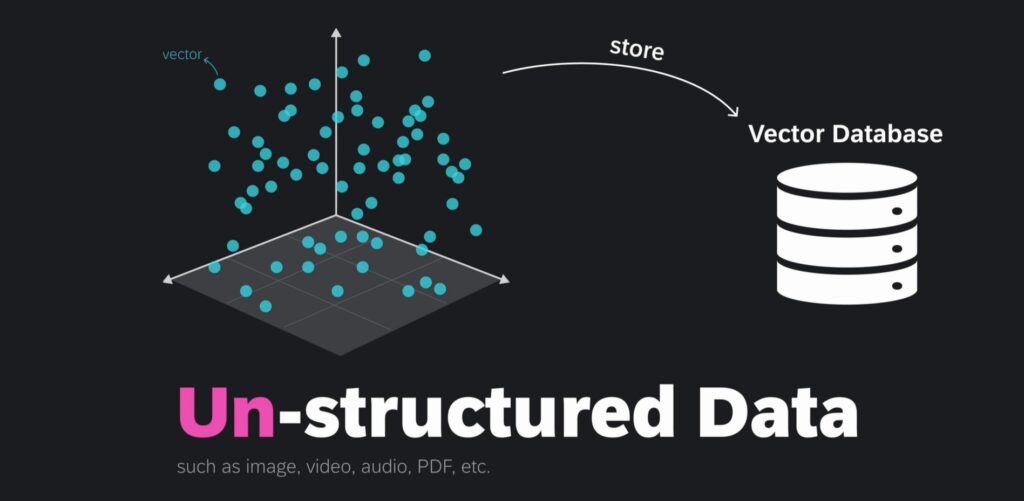
而结构化数据则以表格形式存在,与非结构化数据形成对比。
对于这些非结构化数据,可以基于语义相似度进行相似性搜索(Similarity Search)。
主要用于存储结构化数据,数据通常以行和列的形式组织,适用于存储明确的数据类型,如整数、字符串、日期等。传统数据库通过精确匹配关键词来检索数据,适用于结构化数据的高效查询。
专注于存储和检索高维向量数据,通常用于处理非结构化数据,如图像、文本和声音,由经过特征提取后的向量表示。向量数据库侧重于相似性搜索,它通过语义理解来检索相关结果,不依赖精确匹配来检索相关搜索结果,对拼写错误和同义词有较好的包容性。
当用户问一个问题后,该问题会通过嵌入模型(Embedding Model)转换成向量嵌入(Vector Embedding),用户的问题被转换为高维空间中的数值向量,该向量能够捕捉问题的语义特征,接下来系统会将该向量与向量数据库中的其他向量进行比较,以执行相似性搜索,从而找到最相关的数据条目。
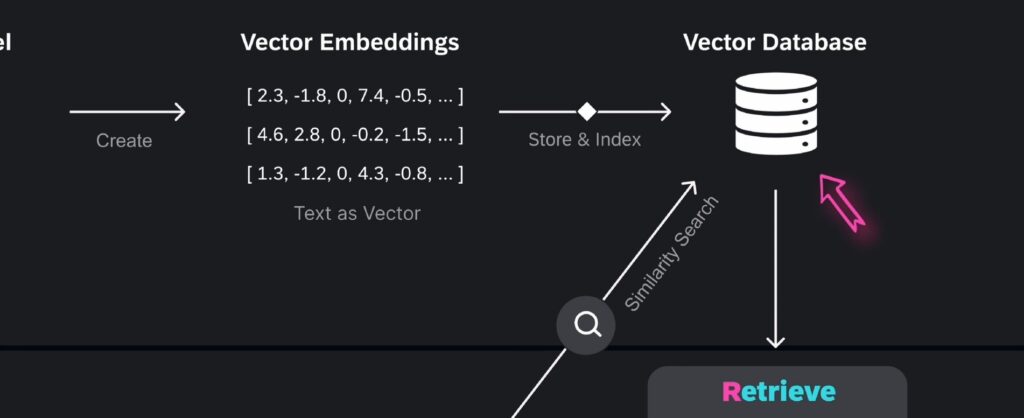
在向量数据库中,检索与用户问题相关的信息的过程,被称为检索(retrieval)。检索式增强生成(Retrieval-Augmented Generation)名称中的首字母“R”正是来源于此。
检索(retrieval)本质上是在向量空间中寻找与查询向量最相似的邻居,这一过程通过计算查询向量与数据库中其他向量之间的距离,找到与之距离最近的邻居,从而返回最相关的对象。
你可以看到 Wolf(狼) 和 Dog(狗) 这两个词在向量空间中靠得很近,因为狗实际上是狼的驯化后代。紧邻狗的位置,你会发现 Cat(猫) 这个词它与狗有一定的相似性,因为两者都是常见的宠物动物。而在右侧更远的地方,则是代表水果的词,如苹果和香蕉,这些词彼此间距离较近,但与动物相关的词,则相距甚远。
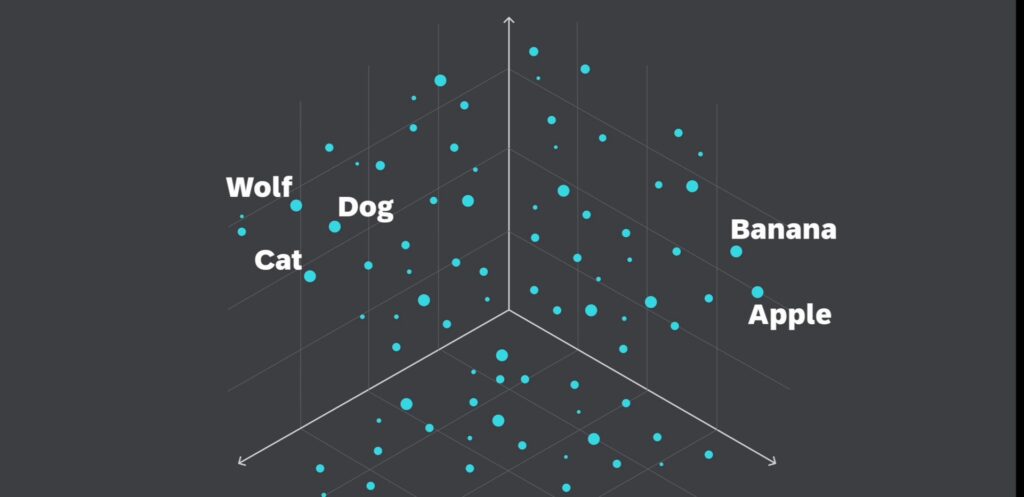
通过向量嵌入,我们可以利用向量空间中对象间的接近程度,来识别和检索相似的对象,这种基于相似度的搜索方法,被称为向量搜索、相似性搜索或语义搜索,它允许我们超越简单的关键词匹配,找到语义上相关的内容。
比如要找到与 Kitten(幼猫) 这个词相似的词,我们可以为这个查询词生成一个向量嵌入,也称为查询向量,并检索其所有最近邻,显然它跟Cat和Dog靠得更近,离Apple和Banana等更远。

怎样计算两个向量之间的距离,来确定它们是否相似?在相似性向量搜索中,最常用的度量距离的指标有:欧式距离、余弦相似度、点积相似度。
欧式距离:——用于测量高维空间中两点之间的直线距离;
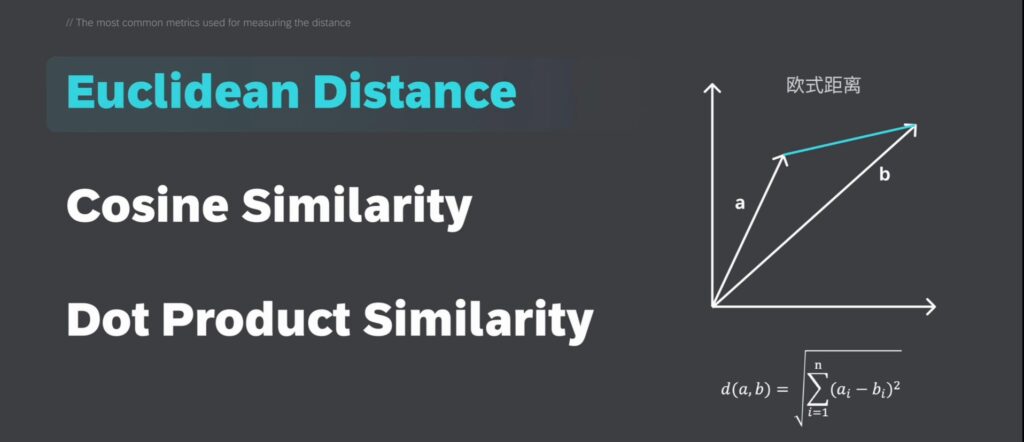
余弦相似度:通过计算两个非零向量的夹角的余弦值,来衡量它们之间的相似性,它常用于基于文本的数据。
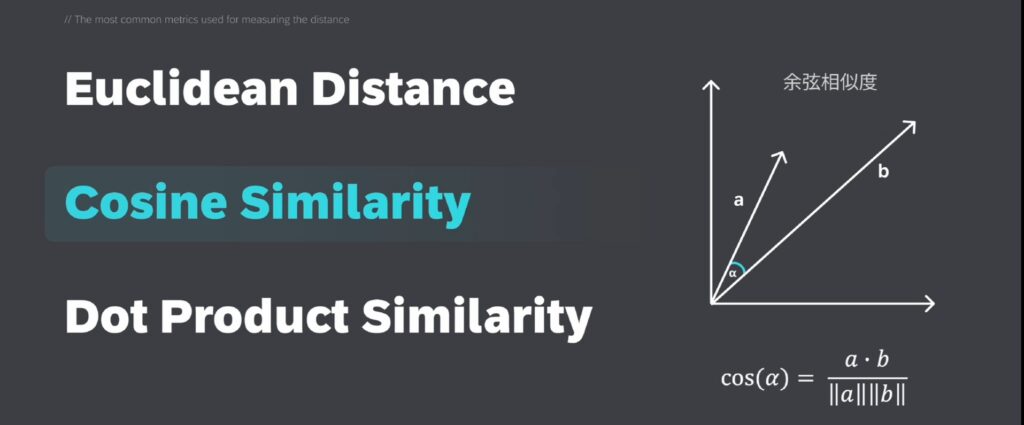
点积(Dot Product)——计算的是两个向量的模长乘积,与它们之间夹角的余弦值的乘积。点积会受到向量的长度和方向的影响。

余弦相似度计算的是两个向量在多维空间中投影后夹角的余弦值,这一度量的优势在于,即使两份文档因为长度不同而在欧氏距离上相距甚远,他们之间的夹角可能仍然很小,从而具有较高的余弦相似度。余弦相似度主要应用于自然语言处理领域。

假设我们要对“Queen皇后”和“King国王”这两个词的相似度进行比较,那么可以将“Queen”和“King”对应的向量,分别带入余弦相似度的计算公式之中,最后求得的值为0.33。
余弦相似度的值范围:从 -1 到 1

余弦相似度通过衡量向量之间的夹角,来评估它们的相似性。如果两个向量之间的夹角很小,它们非常相似,如果夹角较大,它们的相似度就较低。
假设我们有“狼”、“狗”和“鸭子”的“向量嵌入”,“狗”和“狼”向量之间的夹角,比“狗”和“鸭子”向量之间的夹角要小。计算“狗”和“狼”向量之间的余弦相似度,可能会得到一个较高的值,这个值接近 1,因为它们是相似的。而狗和鸭子之间的余弦相似度可能会较低,这个值更接近零,因为他们代表的是具有不同特征的不同动物。
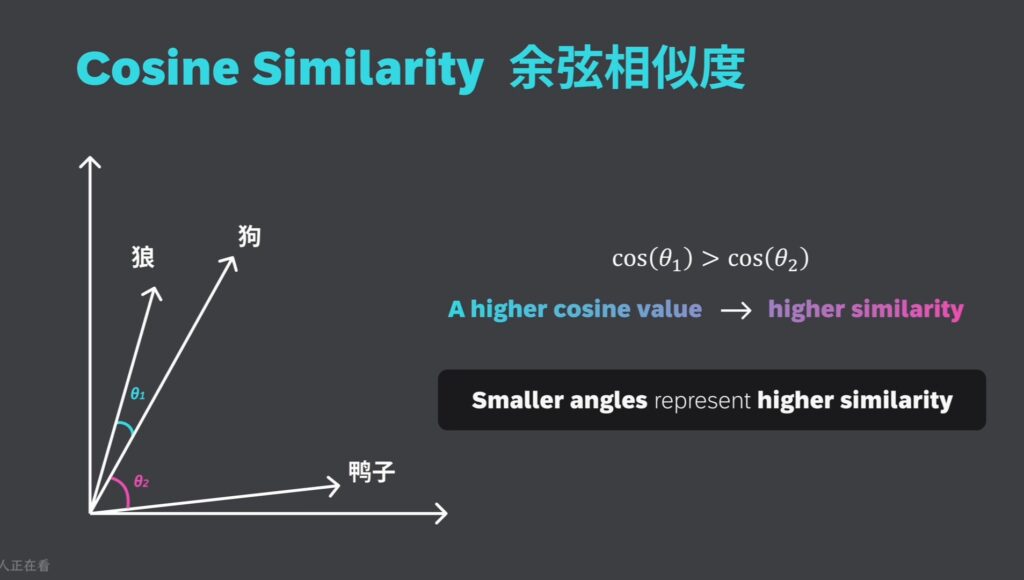
总结一下:夹角越小,余弦值越高,表示相似性越大。
在检索阶段,系统会从海量的文档或数据集中,找出与用户查询最为相关的内容。
随后系统将进一步从中筛选出排名靠前的 k 个文本片段(Top k text chunks)。
接下来,在检索出的 Top k 文本片段基础上,进一步根据与用户查询的相关性,和上下文适配度,进行重新调整,这个重新排序的步骤,叫做 Re-Ranking。
例如:系统从向量数据库中,检索到了10个相关的候选文本块,但它们的初始排序可能并不是最优的,这10个文本块会被送入重排序模型(re-ranking model)中重新进行排序,进而优化他们与用户查询的相关性适配程度,在已完成重新排序的文本块里,筛选出排名靠前的 Top n个文本。
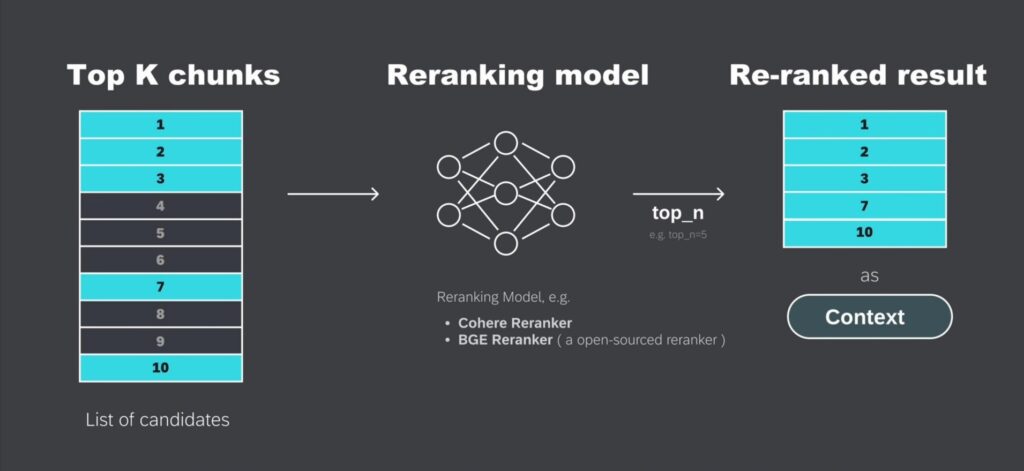
在这个例子中,原先排名第七和第十的文本块,经过重新排序后,成功进入了Top5,这些重新排序过的文本之后将作为上下文相关信息(context)发送给大模型。
简而言之通过re-ranking,系统可以更准确地挑选最合适的片段,从而提升整体响应质量。重新排序过的文本将作为context。上下文相关信息(context)被嵌入到提示词模板中,与用户的问题相结合,从而构建出一个全新的提示词。
这是一段代码示例,在模板中包含了一段指令:“请根据下面的context(上下文相关信息)回答问题,如果没办法依据给出的信息来回答的话,请回复‘我不知道’“。下面的部分是先前从向量数据库中检索到的,与用户问题相关的上下文(context)。最后的部分是用户的问题。
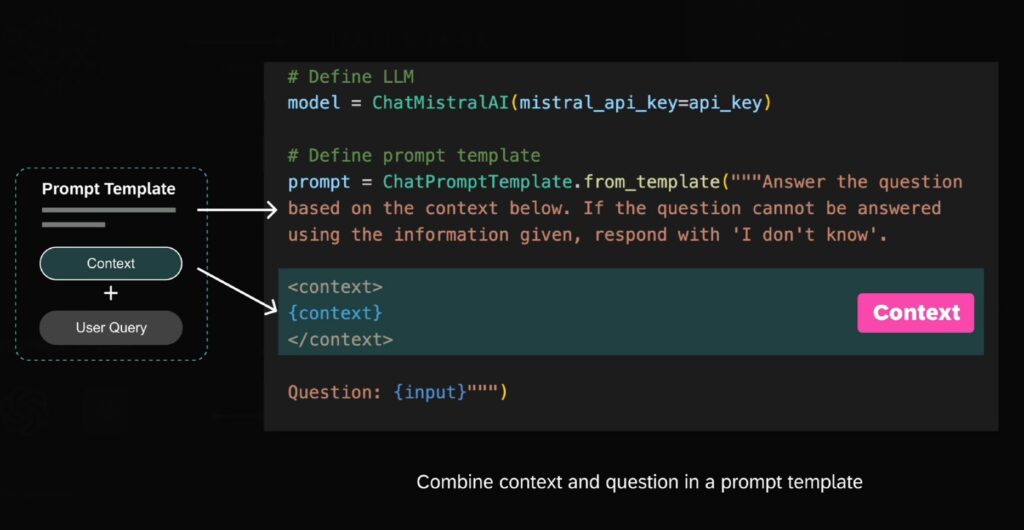
把外部知识库中检索到的相关信息,和用户问题,融合在一个提示词模版(Prompt Template)中,再发给大模型,可以增强GPT的 回答问题和生成内容 的准确性和可靠性。
新的提示词将被发送给大语言模型(如GPT-4o),以生成最终的答案。GPT生成的答案再返回给用户。
RAG系统的核心模块:检索(Restrieval)——本质就是寻找与查询向量相邻的数据点。
如何高效地找到最近邻呢?——向量数据库中的核心算法ANN(”近似最近邻“算法)。
备注:原视频链接 https://b23.tv/uhpFfrc
